|
Jianheng Liu I'm a research engineer at Huawei Noah's Ark Lab in London, working on AI agent research. Before this, I obtained my Master's degree in Robotics and Computation from University College London in 2024 and a Bachelor's degree in Automation from Beihang University in 2023. I'm interested in reinforcement learning, embodied intelligence and robotics. |

|
Research |
|
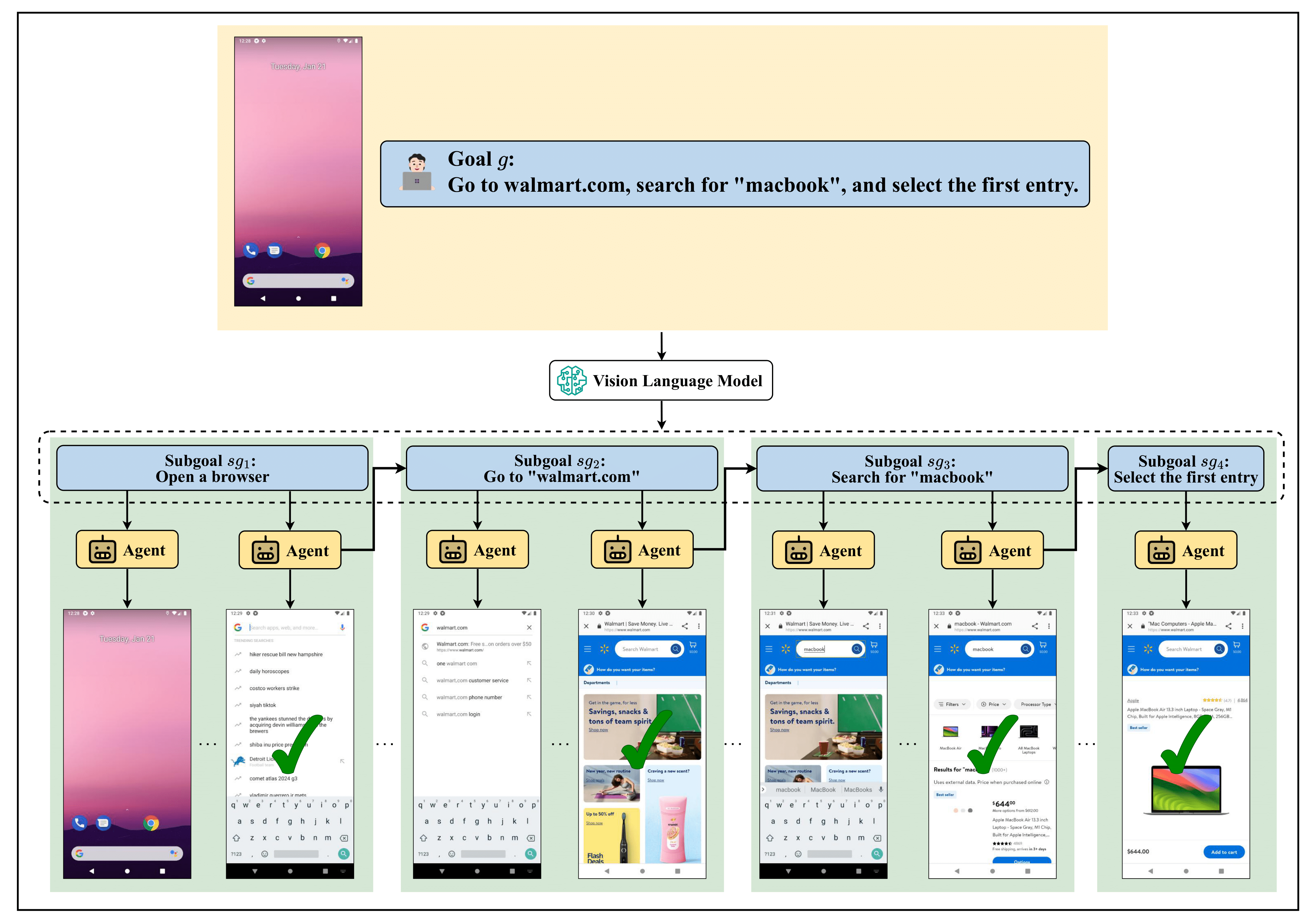
VSC-RL: Advancing Autonomous Vision-Language Agents with Variational Subgoal-Conditioned Reinforcement Learning
Qingyuan Wu*, Jianheng Liu*, Jianye Hao, Jun Wang, Kun Shao Arxiv Preprint, Under Review, 2025 project page / code / arXiv We propose VSC-RL, which enhances vision-language agents by generating subgoals with VLMs. By optimizing the SGC-ELBO, VSC-RL improves learning efficiency and outperforms SOTA methods in mobile device control tasks. |
|
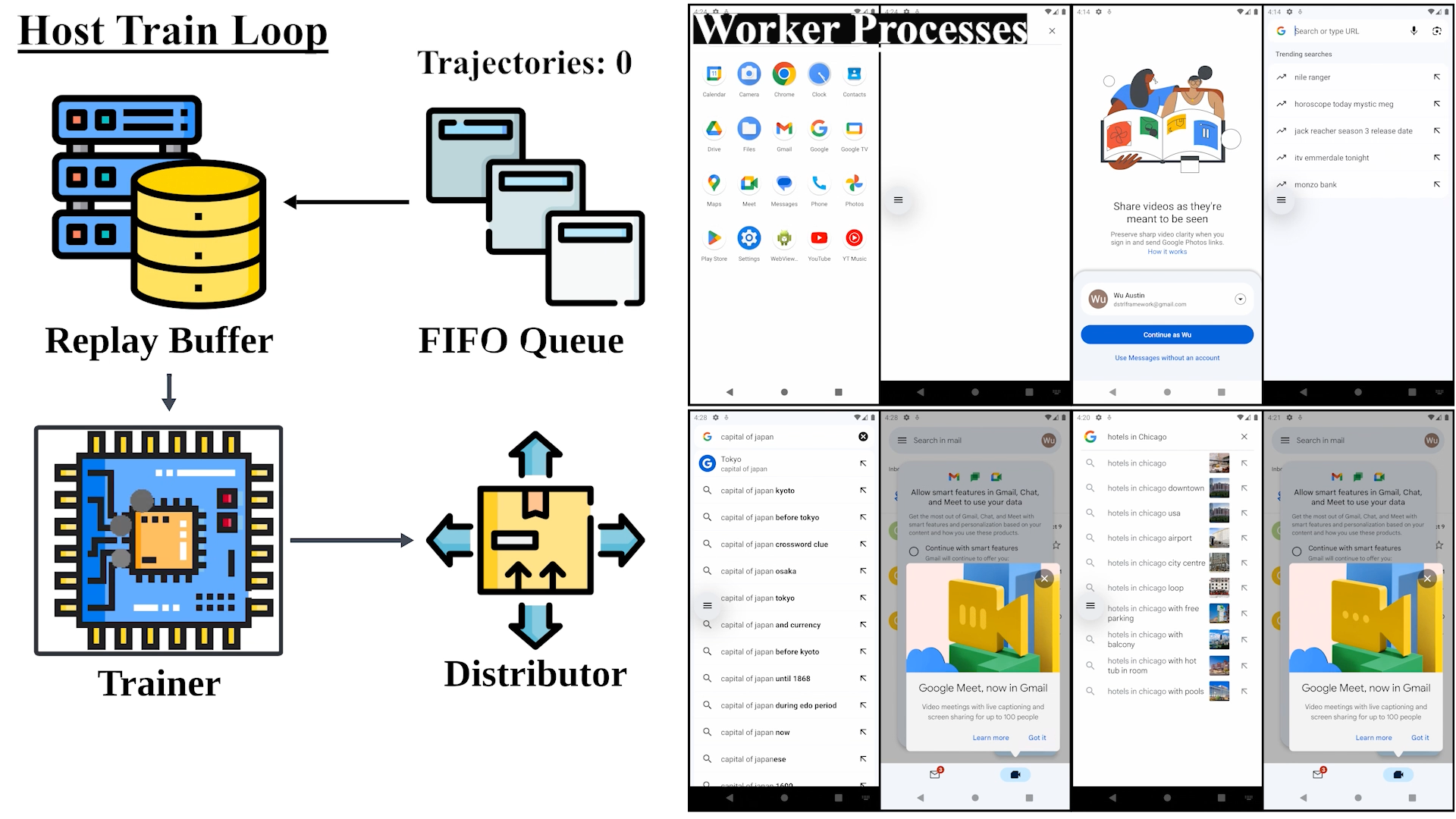
DistRL: An Asynchronous Distributed Reinforcement Learning Framework for On-device Control Agents
Taiyi Wang*, Zhihao Wu*, Jianheng Liu, Jianye Hao, Jun Wang, Kun Shao ICLR, 2025 NeurIPS Workshop, 2024 project page / code / arXiv DistRL introduces a scalable and efficient asynchronous distributed RL framework to enhance online fine-tuning for mobile control agents, achieving superior training efficiency and performance in dynamic real-world tasks. |
|
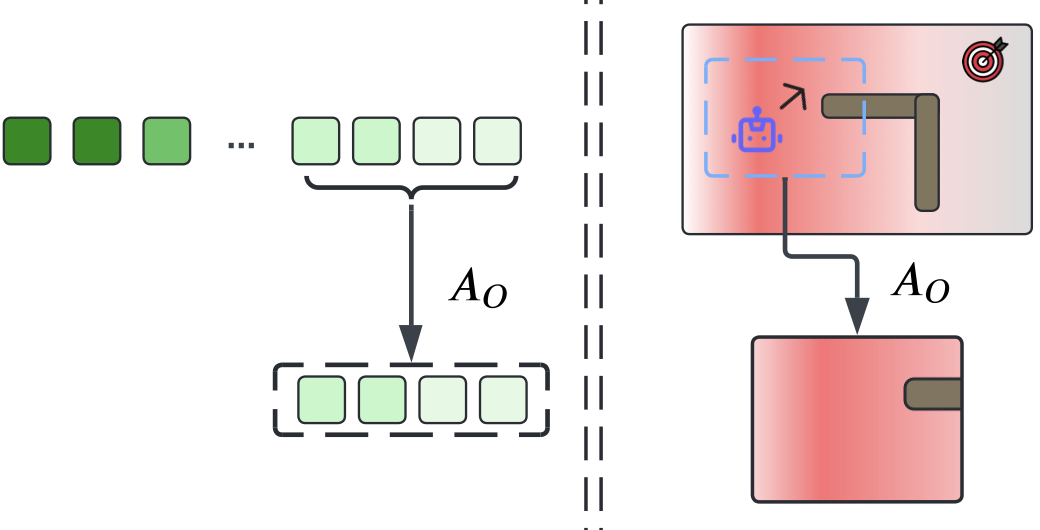
OCMDP: Observation-Constrained Markov Decision Process
Taiyi Wang*, Jianheng Liu*, Bryan Lee, Zhihao Wu, Yu Wu IJCNN, 2025 arXiv OCMDP efficiently balances observation costs and control rewards using a model-free iterative RL framework, achieving superior performance in cost-sensitive decision-making tasks. |

|
Detect an Object At Once without Fine-tuning
Junyu Hao*, Jianheng Liu*, Yongjia Zhao, Zuofan Chen, Qi Sun, Jinlong Chen, Jianguo Wei, Minghao Yang ICONIP, 2024 arXiv Detects unseen objects in diverse scenes without fine-tuning, using a Similarity Density Map for localization and a Region Alignment Network for precise region alignment. |